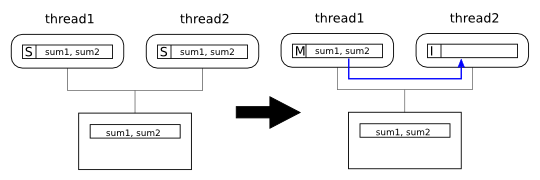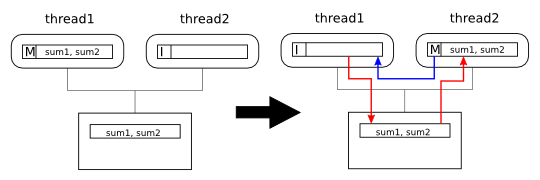| 5.4. Multithreading Problems | ||
|---|---|---|
 | Chapter 5. Memory Performance Problems and Solutions |  |
| 5.4. Multithreading Problems | ||
|---|---|---|
| | Chapter 5. Memory Performance Problems and Solutions | |
Programs with multiple threads can be affected by an entirely new class of performance problems, related to how the data accesses of the threads interact with each other.
Section 3.7, “Multithreading and Cache Coherence” describes how cache coherence affects caching when multiple threads accesses the same cache line. When multiple threads access same cache line and at least one of them writes to it, it causes costly invalidation misses and upgrades. When the threads actually communicate by accessing the same data, this is a necessary overhead.
However, it may also be the case that the threads do not actually communicate. They may be accessing unrelated data that just happen to be allocated in the same cache line. In that case the costly invalidation misses and upgrades are completely unnecessary. By splitting the data accessed by the different threads to different cache lines, the invalidation misses and upgrades can be completely avoided.
Consider this simple example in C:
int sum1;
int sum2;
void thread1(int v[], int v_count) {
sum1 = 0;
for (int i = 0; i < v_count; i++)
sum1 += v[i];
}
void thread2(int v[], int v_count) {
sum2 = 0;
for (int i = 0; i < v_count; i++)
sum2 += v[i];
}
The functions thread1
and thread2 sum the values in the arrays they
get as arguments to the variables sum1
and sum2. Since sum1
and sum2 are defined next to each other, the
compiler is likely to allocate them next to each other in memory, in
the same cache line.
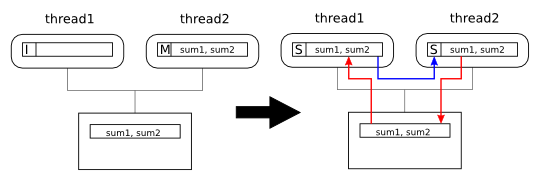
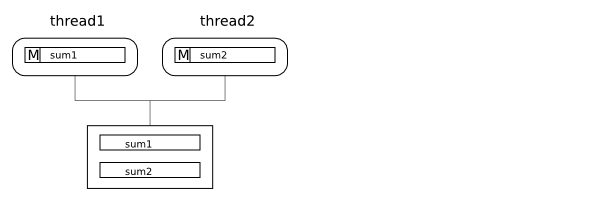
If the functions are run concurrently by two different threads, the execution may then look something like this:
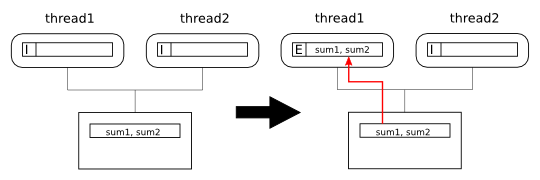
First, thread1 reads sum1
into its cache. Since the line is not present in any other
cache thread1 gets it in exclusive state:
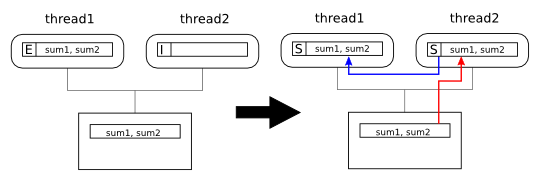
thread2 now
reads sum2. Since thread1
already had the cache line in exclusive state, this causes a
downgrade of the line in thread1's cache and
the line is now in shared state in both caches:
thread1 now writes its updated sum
to sum1. Since it only has the line in shared
state, it must upgrade the line and invalidate the line
in thread2's cache:
thread2 now writes its updated sum
to sum2. Since thread1 has
invalidate the cache line in it's cache it gets a coherence miss, and
must invalidate the line in thread1's cache
forcing thread1 to do a coherence write-back:
The next iteration of the loops now starts,
and thread1 again
reads sum1. Since thread2
just invalidated the cache line in thread1's
cache, it gets a coherence miss. It must also downgrade the line
in thread2's cache,
forcing thread2 to do a coherence write-back:
thread2 finally
reads sum2. Since it has the cache line in
shared state, it can read it without and coherence activity, and
we are back in the same situation as after step 2:
For each iteration or the loops, steps 3 to 6 will repeat, each time with costly upgrades, coherence misses and coherence write-backs.
In reality, the memory accesses would probably not interleave exactly
like this, but the same updates, coherence misses and coherence
write-backs would still occur. In a simple example like this the
compiler may also allocate sum1
and sum2 to registers, avoiding the memory
accesses causing the false sharing, but in a more complex program
they compiler may not be able to do this.
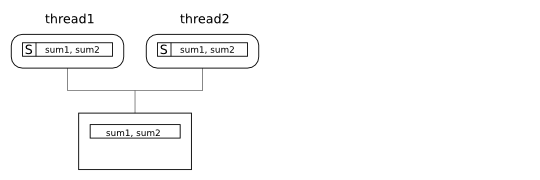
To fix a false sharing problem you need to make sure that the data accessed by the different threads is allocated to different cache lines.
In our simple example we could do this by assuring that both variables are aligned to the start of a cache line. Unfortunately, the C language does not have a standard mechanism to specify the alignment of data. However, most C compilers have some extension to do this. For example, assuming that our processors have 64-byte cache lines and that we are using the GCC compiler, our fixed program would look like this:
int __attribute__((aligned(64))) sum1;
int __attribute__((aligned(64))) sum2;
void thread1(int v[], int v_count) {
sum1 = 0;
for (int i = 0; i < v_count; i++)
sum1 += v[i];
}
void thread2(int v[], int v_count) {
sum2 = 0;
for (int i = 0; i < v_count; i++)
sum2 += v[i];
}
Since the variables are now allocated in different cache
lines, thread1 and thread2
can keep a copy of the cache line they need and execute without
upgrades, coherence misses or coherence write-backs:
There are a number of common causes of false sharing:
Arrays of per-thread data.
A typical programming pattern that causes false sharing is creating an array with one element per thread, such as an array of per-thread counters. Consider this example:
int sums[NUM_THREADS];
void threaded_sum(int thread_num, int v[], int v_count) {
sum[thread_num] = 0;
for (int i = 0; i < v_count; i++)
sum[thread_num] += v[i];
}
This is a function that would be called by multiple threads,
each summing the elements of some array into a per-thread sum
in an array indexed by thread number. This creates a situation
similar to the example with the sum1
and sum2 variables above. Since the
per-thread data is allocated in array it will allocated
together in memory, most likely in the same cache line, causing
false sharing.
Avoid creating such per-thread arrays for frequently accessed data. Use function local variables for frequently accessed data, or assure that the data of each thread is allocated to a separate cache line in some other way, for example, using cache line alignment or padding.
Access patterns in parallelized matrix operations.
Another common cause of false sharing is parallelizations of algorithms that work on matrices or multi-dimensional arrays.
If such parallelizations make a fine grained division of the matrix between the threads, it can cause threads to write to elements adjacent to elements being accessed by other threads. Adjacent elements are likely allocated in the same cache line, making the writes likely to cause false sharing. For example, assume the elements marked in blue and yellow in this example are written by two different threads:
In this case each write by the two threads will invalidate the cache line in the cache of the other thread, causing lots of coherence misses.
A more coarse grained division of the matrix between the threads will allow the threads to work on different cache lines to a greater degree, avoiding false sharing:
If you get problems with false sharing running parallel matrix operations, it is therefore often a good idea to make division of the matrix between the threads more coarse grained.
Accesses to different fields in a structure from different threads.
Accesses to different fields in a structure from different threads can also cause false sharing problems. Consider this example in C:
struct ab {
int a;
int b;
struct ab *next;
};
struct ab *abs;
void inc_a(void) {
struct ab *this_ab = abs;
while (this_ab != NULL) {
this_ab->a++;
this_ab = this_ab->next;
}
}
int sum_b(void) {
int sum = 0;
struct ab *this_ab = abs;
while (this_ab != NULL) {
sum += this_ab->b;
this_ab = this_ab->next;
}
return sum;
}
The function inc_a increments the value of
the a field of each element in
the abs linked list, while the
function sum_b sums the values of
the b field of each element in the list.
If the functions are run concurrently or alternatingly by
different threads, the writes to the a field
of each element in the list by the inc_a
function will invalidate the list elements in the cache of the
thread running the sum_b
function. Similarly, the read of the b field
of each element in the list by the sum_b
function will downgrade the corresponding cache line in the
cache of the thread running the inc_a
function.
In a case like this it is probably best to split the structure into two structures containing the data accessed by each thread. If memory consumption is not a concern, you could also add enough padding between the fields to make sure they end up in different cache lines.
Statically allocated variables.
The example at the beginning of this section about false sharing showed how the statically allocated variables in this program can cause false sharing:
int sum1;
int sum2;
void thread1(int v[], int v_count) {
sum1 = 0;
for (int i = 0; i < v_count; i++)
sum1 += v[i];
}
void thread2(int v[], int v_count) {
sum2 = 0;
for (int i = 0; i < v_count; i++)
sum2 += v[i];
}
In cases like this, if the variables do not need to be statically allocated and are not excessively large you can make them function local variables instead. This causes them to be allocated on the threads' stacks, where they will most likely be safe from false sharing.
If it is not possible to make the variables thread local, you have to change their allocation in memory. One way to make sure that two variables are not allocated to the same cache line is to specify that both should be aligned to the start of a cache line.
Another way is be collect all variables accessed by a thread in a structure, and then add enough padding to the end of the structure to make sure no other variables can be allocated to the same cache line. This is a way to avoid false sharing if the compiler does not allow you to specify the alignment of data.
Dynamically memory allocation.
If your program uses dynamic memory allocation and allocates small data objects, data objects used by different threads may be allocated in the same cache line, causing false sharing.
Trying to allocate larger chunks of memory for use by one thread is probably the best fix in this case. For example, instead of allocating data objects for use by one thread individually you can allocate an array of data objects at once. This may reduce the interleaving of data objects used by different threads and thereby also false sharing.
Otherwise, aligning the data objects causing false sharing to the beginning of a cache lines is again a way to avoid false sharing. Depending on the operating system you are using there may be memory allocation functions you can use to do this.
Threads in a multithreaded programs often communicate by reading and writing shared data in memory. Section 3.7, “Multithreading and Cache Coherence” describes how this causes costly upgrades, coherence misses and coherence write-backs. But, if the threads truly communicate unlike false sharing described in Section 5.4.1, “False Sharing”, this is to some degree an unavoidable cost.
However, there is a performance cost for each cache line transferred from the cache of one thread to another, so you want to minimize the number.
One way to measure the efficiency of the communication is to calculate communication utilization, the fraction of each transferred cache line that was actually written by the producer and read by the consumer, as described in Section 4.7, “Communication Utilization”.
The communication utilization is similar to fetch utilization and write-back utilization, but measures the efficiency of the communication between caches instead of between the cache and memory. If the communication utilization is low it means we are moving unused data between the processors. By using the communicated cache lines more efficiently it may be possible to reduce the communication overhead.
The causes of poor communication utilization are largely the same as the causes of poor fetch utilization and poor write-back utilization:
Unused fields in structures.
Unused fields in a structure being written by one thread and read by another may waste space in the communicated cache lines. See Section 5.1.1, “Partially Used Structures” for more information.
Alignment problems.
Data alignment problems may cause unused padding in or between communicated data structures. See Section 5.1.3, “Alignment Problems” for more information.
Dynamic memory allocation.
If the communicated data objects have been dynamically allocated, they may be spread out in memory and be interleaved with the dynamic memory allocator's bookkeeping data. See Section 5.1.4, “Dynamic Memory Allocation” for more information.
Irregular access patterns.
Arranging the communicated data in a way that causes irregular access patterns may cause poor communication utilization. See Section 5.2.2, “Random Access Pattern”.
Too fine grained communication.
One cause of poor communication utilization that does not correspond to a fetch or write-back utilization problem is too fine grained communication. If the communication between two threads is too fine grained, the communicated data may not fill entire cache lines and unused data is transferred between the caches.
For example, assume that we have a producer thread and a consumer thread communicating 8-byte data objects through a queue based on a circular buffer, and that they run on a computer with 64-byte cache lines.
If the producer writes one data object to the queue at a time and then signals the consumer to read it, a cache line with only 8 bytes of useful data out of the 64 bytes will be sent from the producer to the consumer. This will cause one upgrade in the producer thread's cache and one coherence miss in the consumer thread's cache for each communicated object.
However, if the producer thread knows that there are more data objects waiting to be sent, it can delay signaling the consumer thread until it has written a whole cache line of eight data objects to the queue. This way the entire communicated cache line is used, and you only get one upgrade and one coherence miss for every eight data objects.
Making the communication more coarse grained is also likely to reduce the amount of synchronization between the threads, and thereby reduce the synchronization overhead.
| |  | |
| 5.3. Non-Temporal Data |  | 5.5. Common Data Structures |